A Memory That Follows Me
Building shared memory infrastructure across AI tools and sessions
I use AI coding assistants daily, across multiple machines, multiple projects, and multiple tools. Each of them has gotten remarkably good at remembering things within their own walls. Claude Code has its CLAUDE.md files and auto-memory. ChatGPT has conversation history. Cursor has project context. The tools themselves are not the problem. The problem is that their memories don't travel with me.
When I switch from Claude Code to Codex, everything I've established in one tool stays behind. When I move to a different workstation, the context I've built up over days of work doesn't come along. And when I have a conversation with OpenClaw, none of that knowledge shows up in my coding sessions the next morning. Every tool remembers on its own, but nothing carries across.
I kept running into the same friction: preferences I'd established in one place needed re-establishing in another, project decisions captured by one tool were invisible to the rest, and context accumulated in fragments across a half-dozen different systems with no way to unify it.
So I built mnemo, a centralized memory system that follows me across sessions, machines, and tools. It currently integrates with Claude Code, OpenAI's Codex CLI, and OpenClaw, but the API is client-agnostic so adding new tools is straightforward.
The real issue is architectural: memory is treated as a feature of each individual client rather than shared infrastructure. If you think about how humans actually work, knowledge doesn't live inside the hammer or the screwdriver, it lives in the person holding them. When I switch tools, my brain comes with me. When I switch workstations, I don't lose everything I learned yesterday (ok, not always :D).
I wanted the same thing for my AI tools: a central memory that any client can write to and read from, so that context accumulates across all of them instead of fragmenting.
Why Bedrock AgentCore Memory
I could have built memory from scratch (a vector store, some embeddings, a retrieval layer, consolidation logic) but Amazon Bedrock AgentCore Memory already solves the hard parts. It handles event ingestion, built-in extraction strategies for preferences, facts, and episodic memory, namespace-scoped retrieval, and it does all the heavy lifting of deciding what's worth remembering from a conversation.
The key insight is that AgentCore separates events from memories. You push conversation turns (events), and AgentCore asynchronously extracts structured memories using configurable strategies. This means the write path is fast (just an API call to store the event), and the extraction happens in the background without blocking the client.
AgentCore also supports self-managed memory strategies alongside its built-in ones, which turned out to be the most powerful aspect of the whole system. More on that in a moment.
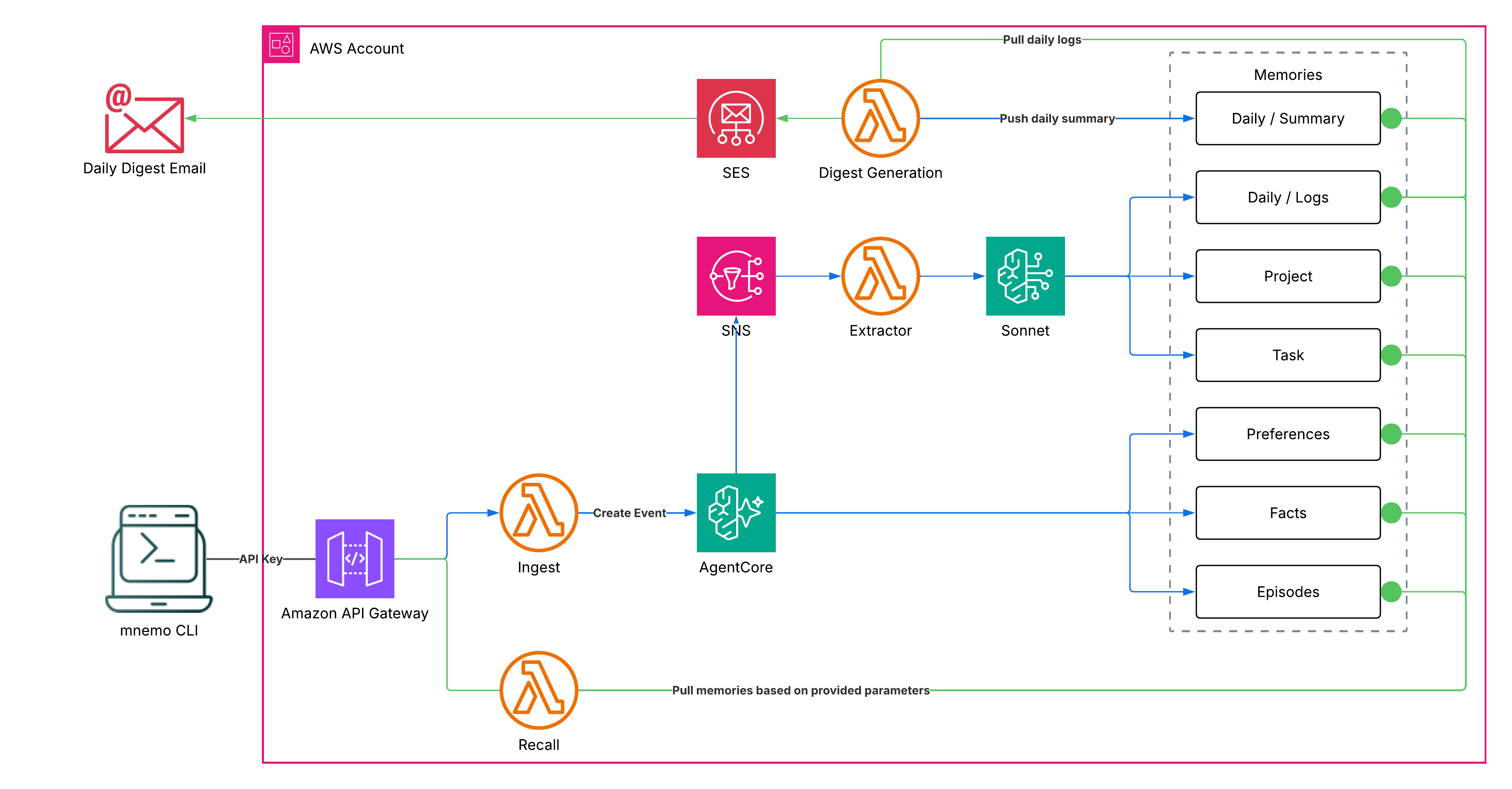
The write path pushes conversation turns through an API Gateway to the Ingest Lambda, which calls AgentCore's CreateEvent. AgentCore processes the event asynchronously: built-in strategies extract preferences, facts, and episodes, while the custom strategy triggers the Context Extractor through SNS for project, task, and daily log memories. A separate digest Lambda runs on a schedule to consolidate the day's logs into a structured summary and optionally email it.
The read path is fully opt-in: the caller selects which dimensions to retrieve, and the Recall Lambda queries only those namespaces in parallel. No dimensions are returned by default. A recall that touches all seven dimensions still comes back in under a second.
How memory is organized
mnemo organizes memories into seven dimensions, three handled automatically by AgentCore and four managed by a custom extraction pipeline:
Built-in (AgentCore handles these automatically):
- Preferences: coding style, tool choices, communication style, workflow habits
- Facts: general knowledge, learned facts, technical context
- Episodes: structured episodes with situation, intent, and reflection
Self-managed (custom Lambdas extract these):
- Project: architecture decisions, tech choices, design rationale per project
- Task: domain-specific patterns (coding insights, meeting notes, study summaries)
- Daily Log: append-only detailed activity entries written throughout the day by the context extractor
- Daily Summary: a structured end-of-day digest generated by a scheduled Lambda, covering projects worked on, decisions, learnings, time allocation, and a brief reflection
The self-managed dimensions are where things get interesting. When AgentCore finishes processing an event, it triggers an SNS notification. A context extractor Lambda reads the conversation payload from S3, sends it to Claude Sonnet for classification and extraction, and writes the results back as memory records in their respective namespaces. Project and task facts are consolidated (merged with existing records), while daily log entries are appended throughout the day.
A separate daily digest Lambda runs on a configurable schedule (via EventBridge Scheduler), reads all the day's log entries, synthesizes them into a structured summary using Claude Sonnet, writes the summary to a separate namespace, and optionally emails it to you via SES. This means you get both the raw granular log and a polished reflection, and recall automatically prefers the summary when it exists, falling back to the raw log mid-day before the digest has run.
Task domain classification uses a configurable list of domains (coding, studying, meeting, general by default), while project detection relies on the git repo folder name, which means sessions outside a git repo only get global memories with no project context. A simple heuristic, but it works surprisingly well in practice.
Memory consolidation: the part that keeps things sane
Without consolidation, self-managed memories grow unbounded. Every session adds new facts, and after a week you're retrieving 50 nearly identical statements about the same project. I learned this the hard way when I noticed the preferences namespace returning a wall of duplicated content.
The consolidation algorithm is straightforward: when the Context Extractor writes new memories for a namespace, it first reads all existing records, sends both the old and new content to Claude Sonnet with type-specific instructions ("merge overlapping facts, keep the most recent version, drop low-value details"), writes the consolidated record, and deletes all the old ones.
This means each namespace converges toward a single, up-to-date record rather than an ever-growing pile. It's lossy by design (you lose version history), but the trade-off is worth it because you get a clean, coherent memory that fits in context rather than a sprawling archive that overwhelms it.
Client integrations and the API
mnemo currently integrates with Claude Code, Codex, and OpenClaw, but the system is deliberately client-agnostic. The entire interface is two HTTP endpoints and a CLI, so anything that can make a curl call can participate. Installing a built-in integration is a single command:
mnemo install claude-code
mnemo install codex
mnemo install openclaw --channels telegram,whatsapp
The API is simple enough to use directly too. Pushing context is a POST with a session ID, conversation turns, and optional metadata:
mnemo push \
--session "meeting-$(date +%s)" \
--turns '[{"role":"user","content":"Switching auth to Cognito"}]' \
--project my-saas \
--source meeting-bot
Recalling context is a GET where you explicitly select which dimensions you want. Nothing is returned by default:
mnemo recall --project my-saas --task coding --daily
mnemo recall --preferences --facts --episodes
mnemo recall --all
That's it. A meeting note pushed from a Slack bot becomes available when I'm coding the next morning. A design decision captured in one tool shows up in another. The daily summary reflects everything I did, regardless of which tool I used to do it.
What this actually looks like in practice
Here's what a typical day looks like with mnemo running:
I open Claude Code in the mnemo repo on my laptop. The session-start hook fires, recalls my preferences, project facts, and yesterday's daily summary from mnemo. On top of whatever Claude Code remembers locally, it now has the full cross-tool context: what I worked on in Codex yesterday, decisions from last week's Telegram conversation, the daily summary of everything I did.
I work for a couple of hours. Every prompt pushes context to mnemo, with the cursor deduplicating so only new turns are sent. AgentCore extracts preferences and facts in the background, while the Context Extractor writes project decisions and appends detailed log entries.
I switch to Codex for a different project. The hooks detect the new git repo automatically and recall project-specific memories alongside the same global preferences and facts.
I have a conversation about physics on Telegram through OpenClaw. The hook captures the exchange and pushes it to mnemo, where the Context Extractor classifies it as "studying" and writes the insights to the task namespace.
Later, I open Claude Code on a completely different machine. Claude Code's own memory is local to the first machine, but mnemo's recall brings everything forward: the combined context from the Claude Code, Codex, and OpenClaw sessions, regardless of where they happened.
At 7pm, the daily digest Lambda fires. It reads all the log entries from the day, generates a structured summary with sections for projects, decisions, learnings, and a reflection, writes it to memory, and emails it to me.
The daily digest is something I didn't expect to value so much. Being able to recall what I actually accomplished across a full day of work, aggregated from all sessions, all projects, and all tools, turns out to be genuinely useful for standups, weekly reviews, and just general "wait, what did I do yesterday?" moments. And because the summary lives in the daily namespace, the next morning's session-start hook can recall it automatically.
Try it yourself
mnemo is on GitHub. It deploys as a CDK stack to your AWS account and takes about 10 minutes to set up. You'll need Node.js 22+, an AWS account with CDK bootstrapped, and Bedrock AgentCore Memory access enabled in your region. The whole system runs on serverless (API Gateway, Lambda, SNS, S3, AgentCore), so cost scales with usage.
For reference, over a 3-day stretch of heavy personal use (268 events ingested, ~5,300 conversation turns, ~270 recalls across Claude Code, Codex, and OpenClaw), the total was $1.75, with AgentCore accounting for most of it. That works out to roughly $0.58/day.
We keep building AI tools that remember things, and then trapping those memories inside themselves. Every client reinvents the same wheel: local files, conversation logs, embedded context. It's not a memory problem, it's a plumbing problem. The knowledge is there, it just can't move. I don't think mnemo is the final answer, but for my personal use-case it is definitely a game changer.